upd 2021/8/12:
修复缩进,大量更改了一些刷新我认知的东西。
upd 2022/3/9: 修代码与排版。
LZC
大佬表示多项式应该先学生成函数等等我不会的东西,所以别看了。
以下 99% 的内容没有证明,也不会用很标准的数学形式,只可意会。
由于我随时可能忘光回来复习所以特别啰嗦。
所有的代码都经过了结构性优化,其实适合背板子不适合理解。
代码都很短,不用担心。
警告:以下所有代码都不能通过洛谷上的模板题P3803,因为数组没开够。
前置知识
定义
设 ,则 为一个 次多项式。完完全全的废话
设有一个 次多项式 与一个
次多项式 , 与 的多项式乘法卷积为 ,则 .完完全全的废话x2
反正直接理解成无限进制下整数乘法就行。
复数
设 为虚数单位,则
( 均为实数)为复数,其中 为该复数的实部, 为该复数的虚部。
乘法即为:
重要:由复数点组成的集合叫复平面(也就是把 看作为坐标 )。
所以可以定义绝对值为其到原点的距离 。
其实这玩意就是平面直角坐标系,相加满足平面直角坐标系中向量加的四边形法则,相乘满足极坐标系中的辐角相加,模长相乘。
反正我们只研究单位根不用管那么多。
点值表示法
还是那个多项式
,在学习拉格朗日插值的时候我们就知道了 个点可以确定一个 次多项式,所以
可以用来表示一个
次多项式。
这个玩意没有什么用处,除了一个性质:
可以表示为
嗯,为什么呢,你考虑一个点意味着什么, 满足 .
而我们显然有:
所以:
总而言之,点值表示法(满足取的点集的横坐标相等)表示的多项式相乘,直接把代入数相同的项乘起来就行。
FFT
Fast Fourier Transform 快速傅里叶变换
给出多项式 求多项式 (也就是上面提到的卷积)。
这个柿子非常常见,而且看起来非常可以优化。
所以对着这个柿子,我们想想考虑怎么优化。
然后我们发现似乎并不能优化。
所以把这个柿子扔掉吧!你看,我们可以直接把两个点值表示的多项式 乘起来!
不过,因为 次多项式与 次多项式的积会有 次,所以我们的点值表示应该有至少
个点才对。当然,这仍是 的。
但是这是个虚假的 ,因为这个点值表示法乘出来完全没有用。
于是尝试化为一般的多项式,发现只能 插值并没有什么意义。
而且由一般的多项式化为点值需要把 个点丢进去算也是 的。
于是某人想出一个好主意:把一些奇怪的
带进去算点值,以使用某些性质加速运算。
单位根
考虑
,这样的复数有一个性质, 其若干次幂的绝对值均为1.
因为辐角相加,模长相乘所以是对的,我才不会告诉你我暴力展开然后不会因式分解才这样写的
这样的点将在复平面上形成一个半径为1的圆(单位圆),于是可以定义 为从点 开始逆时针旋转 个单位圆得到的点。
因为辐角相加,模长相乘 ,所以
的若干次方有一个很棒的性质: 为从点 开始逆时针旋转 个单位圆得到的点。
所以,当 时, 的若干次方呈:
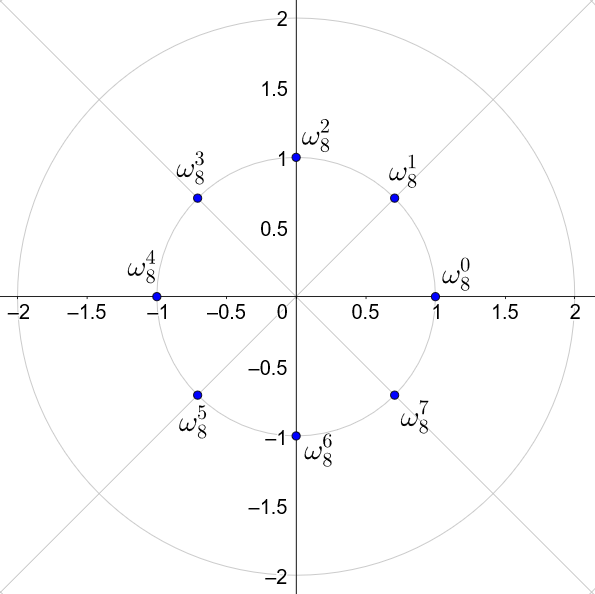 unit circle
unit circle
还是因为辐角相加,模长相乘 ,所以:
我们惊奇的发现这就是分数!
对了,这里提一个很重要的东西,
。
因为 是
,而显然按照我们的定义单位根应该是一整个圆即 所以乘二。
接下来是两个重要的东西:
周期引理
我们可以感性理解一下:
后面那个东西请想象一个点在圆上转了半圈所以对原点对称,记住这个负号不仅对实部取负,虚部也取负。
证明到一半夭折了。
以及,这样意味着我们实际使用的单位根只有
个,因为剩下的一半我们可以对已有的一半取负得到(实际上,一半的单位根用不上,这就是我们优化的基础)。
其实这个式子似乎没有名字,不过有个与它相似的叫周期引理,而我主观的认为它们一致:
消去引理
这不就是分数的约化还要证明?
另外,有的地方会提到一个折半引理:
请恕我实在不明白这个东西跟消去引理的区别。
DFT
Discrete Fourier Transform 离散傅里叶变换
用于把多项式转换成点值表示。
合着才开始呢?
接下来会有一堆式子,不过这些式子在理解了复数之后并不复杂。
对于 次多项式 尝试按 的次数的奇偶性拆开,变成 与 ,于是 。
整理 :
现在把 中的 提出去,仍然叫 .
于是原式变成了:
话说我长期以为要直接对这两个柿子分治导致不会整。
现在假设我们往 里面丢一个
,那么变成了:
我们发现并没有什么用,于是再丢一个 进去:
由于这个多项式中的
都只有偶数次幂,所以负号没有什么用,我们把负号去了:
我们发现这与上面
的柿子只有一个符号不同:
因为你求出了 与 之后就可以得到 与
。前两个多项式的总长为
,而后两个的总长为
。并且,这个过程可以递归进行,每轮多项式的规模缩小一半,于是总的时间复杂度为
。
于是可以分治了!吗?
用这种方式乘出来的东西是点值表达式,但我们还要转换回系数表达才能用。
怎么做呢,我也不会
总之就是把所有的
的虚部取负(或者专业一点,变为共轭复数),然后做一次完全一样的
DFT ,然后除一个
就行。这个过程有一个专门的名字 IDFT
(逆离散傅里叶变换)。知道就好没什么用
具体的证明要扯出范德蒙德矩阵来,大家的线性代数学的比我好,反正我不会。
不过还是贴一个有证明的
blog好了,感兴趣可以看一看。
CODE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| #include<cmath>
#include<cstdio>
#include<iostream>
#define N 262145
#define uni unsigned
#define reg register
#define lf long double
#define cp(a,b) (complex{a,b})
using namespace std;
const lf PI=acos(-1);
uni n,m,lim=1,l=-1,r[N];
char BuF[1<<26],*InF=BuF;
struct complex{
lf r,i;
complex operator+(complex b){return(cp(r+b.r,i+b.i));}
complex operator-(complex b){return(cp(r-b.r,i-b.i));}
complex operator*(complex b){return(cp(r*b.r-i*b.i,r*b.i+i*b.r));}
}a[N],b[N];
template<typename T>void read(T &x){
for(;47>*InF||*InF>58;++InF);
for(x=0;47<*InF&&*InF<58;x=x*10+(*InF++^48));
}
void fft(complex *a,uni lim,bool mode){
if(lim>1){
uni half=lim>>1;
complex a0[half],a1[half];
for(uni i=0;i<lim;i+=2) a0[i>>1]=a[i],a1[i>>1]=a[i+1];
fft(a0,half,mode);fft(a1,half,mode);
for(uni i=0;i<half;++i){
complex temp=cp(cos(i*PI/half),mode?-sin(i*PI/half):sin(i*PI/half))*a1[i];
a[i]=a0[i]+temp;
a[i+half]=a0[i]-temp;
}
}
}
int main(){
fread(BuF,1,1<<26,stdin);
read(n);read(m);
for(reg uni i=0;i<=n;read(a[i++].r));
for(reg uni i=0;i<=m;read(b[i++].r));
for(;lim<=n+m;++l) lim<<=1;
fft(a,lim,0);
fft(b,lim,0);
for(reg uni i=0;i<=lim;++i) a[i]=a[i]*b[i];
fft(a,lim,1);
for(reg uni i=0;i<=n+m;++i)
printf("%d ",(int)(a[i].r/lim+0.5));
return(0);
}
|
但这个东西没有什么用,甚至本地跑直接栈溢出。
小优化
考虑如何进行优化,发现 DFT
在分治前除了划分奇偶啥也没干,考虑直接划分到位,自底向上。
根据手玩可以发现对于位置
,其最后划分完成的数为其二进制反转。例如 这个位置最后放的是 。
大致的过程就是我们把系数放到最后的位置,由下至上做 DFT ,因为 DFT
的过程不会因为系数的改变而改变,所以我们中间不用再管系数是什么的问题,只需要按照流程算数就行了。
这个在很多地方被称为蝴蝶变换,但是有些地方也拿蝴蝶变换指代我们分治的过程。
为了防止任何的歧义,这里一个也不拿出来当名称。
再提一次:有用的
一共只有
个(因为虚部为负的
个会被我们的分治优化掉,彻底用不上)。
可以预处理出
个单位根减少三角函数的调用次数,而且对于一种按照定义,取 然后求幂来得到 的方式而言,精度更高。
一般而言,只要你不在
的循环里面使用三角函数,(相对与 次复数乘法而言)它们对时间的影响就可以忽略不计。
有些时候你会见到有些地方预处理单位根时不乘二,也即
,实际上这种方式按顺序求出来的是按照原先定义的 。
不过,如果你去(把那些代码放到本地)调试看看,你会发现其中多出来的
的部分根本用不上。
所以下面的所有代码已经调整过了不会有这个问题,这样如果这篇文章被人看到的话,看到的人就不会像我一样被刷新认知了。
以及,在上方已经使用的,手写复数代替标准库中的复数。
CODE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| #include<cmath>
#include<cstdio>
#include<iostream>
#define N 262145
#define uni unsigned
#define reg register
#define lf long double
#define cp(a,b) (complex{a,b})
using namespace std;
const lf PI=acos(-1);
uni n,m,lim=1,l=-1,r[N];
char BuF[1<<26],*InF=BuF;
struct complex{
lf r,i;
complex operator+(complex b){return(cp(r+b.r,i+b.i));}
complex operator-(complex b){return(cp(r-b.r,i-b.i));}
complex operator*(complex b){return(cp(r*b.r-i*b.i,r*b.i+i*b.r));}
complex operator/(uni b){return(cp(r/b,i/b));}
complex operator~(){return(cp(r,-i));}
}a[N],b[N],wn[N];
template<typename T>void read(T &x){
for(;48>*InF||*InF>57;++InF);
for(x=0;47<*InF&&*InF<58;x=x*10+(*InF++^48));
}
void dft(complex *a){
for(reg uni i=0;i<lim;++i)
if(i<r[i]) swap(a[i],a[r[i]]);
for(reg uni mid=1,cnt=l;mid<lim;mid<<=1,--cnt)
for(reg uni i=mid<<1,j=0;j<lim;j+=i)
for(reg uni k=0;k<mid;++k){
complex x=a[j+k],y=wn[k<<cnt]*a[j+mid+k];
a[j+k]=x+y;
a[j+mid+k]=x-y;
}
}
int main(){
fread(BuF,1,1<<26,stdin);
read(n);read(m);
for(reg uni i=0;i<=n;read(a[i++].r));
for(reg uni i=0;i<=m;read(b[i++].r));
for(;lim<=n+m;++l) lim<<=1;
for(reg uni i=1;i<lim;++i)
r[i]=(r[i>>1]>>1)|((i&1)<<l);
for(reg uni i=0,r=lim>>1;i<r;++i)
wn[i]=cp(cos(i*PI/r),sin(i*PI/r));
dft(a);dft(b);
for(reg uni i=0;i<lim;++i){
a[i]=a[i]*b[i];
wn[i]=~wn[i];
}
dft(a);
for(reg uni i=0;i<=n+m;++i)
printf("%u ",(uni)(a[i].r/lim+0.5));
return(0);
}
|
NTT
Number-Theoretic Transform 数论变换
这里提一下大部分地方都把 NTT 的全称写成了 (Fast) Number Theory
Transform 是不对哒,维基上写的是 Number-Theoretic Transform
。以及,中文名似乎也没有“快速”。
总所周知大部分题目都会有模数,我们考虑是否对于一个剩余系有一些更好的东西来代替掉精度又慢的复数。
答案是有的,对于一个 (这个
还要满足一些性质,等一会提到)的原根 ,其满足:
对了,整数
原根的定义是一个整数 满足存在一个
使得 成立且 是满足这个柿子的最小的 .
当然,这个定义不拿来推柿子没什么用。反正我也不会证它为什么满足上面的性质
至于怎么求原根的话,可以用 BSGS
然后枚举一下,原根有个非常非常松的上界,它小于 ,不过一般出题人会用的模数原根都是
3 .
因为能用的模数必须满足设其表示为 ( 可以是合数,要求 最大),则 大于数据中的 (或者换种说法:满足 这里的 为调整过后的)。
如果实在不放心可以在这里查 NTT
能用的模数的原根。
悲惹,这个 blog 木大了。现在可以看这个。
CODE
这个是更新的进行了常数优化的板子,能以比较好的速度完成常规要求。
在 UOJ#34 上取得了恰好
ms 的用时,附近似乎都是 1.5 倍
FFT 的提交(下面会提到,但是不会有,因为我很菜)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| #include<cmath>
#include<cstdio>
#include<iostream>
#define N 262145
#define mod 998244353
#define uni unsigned
#define ll uni long long
using namespace std;
const uni M0=0x7fffffff;
uni n,m,lim=1,l=-1,r[N],a[N],b[N];
uni power(uni base,uni t){
uni re=1;
for(;t;t>>=1,base=(ll)base*base%mod)if(t&1)re=(ll)re*base%mod;
return(re);
}
struct pre{
uni g[N+N]={0},gi[N+N]={0};
constexpr pre(){
for(uni i=0,t=0;(t=1<<i)<N;++i){
g[t|1]=power(3,(mod-1)/(t<<1));
gi[t|1]=power(3,mod-1-(mod-1)/(t<<1));
g[t]=gi[t]=1;
for(uni j=t+2;j<t<<1;++j){
g[j]=(ll)g[j-1]*g[t|1]%mod;
gi[j]=(ll)gi[j-1]*gi[t|1]%mod;
}
}
}
}pre;
char BuF[1<<26],*InF=BuF;
template<typename T>void read(T &x){
for(;47>*InF||*InF>58;++InF);
for(x=0;47<*InF&&*InF<58;x=x*10+(*InF++^48));
}
int main(){
fread(BuF,1,1<<26,stdin);
read(n);read(m);
for(uni i=0;i<=n;read(a[i++]));
for(uni i=0;i<=m;read(b[i++]));
for(;lim<=n+m;++l) lim<<=1;
for(uni i=1;i<lim;++i)
r[i]=(r[i>>1]>>1)|((i&1)<<l);
for(uni i=0;i<lim;++i)
if(i<r[i]){
swap(a[i],a[r[i]]);
swap(b[i],b[r[i]]);
}
for(uni mid=1,cnt=0;mid<lim;mid<<=1,++cnt)
for(uni i=mid<<1,j=0;j<lim;j+=i)
for(uni *x0=a+j,*y0=x0+mid,*x1=b+j,*y1=x1+mid,k=0,*g=pre.g+(1<<cnt);k<mid;++k,++g,++x0,++y0,++x1,++y1){
uni t0=(ll)*g**y0%mod,t1=(ll)*g**y1%mod;
if((*y0=*x0-t0)>M0) *y0+=mod;
if((*x0+=t0)>M0) *x0-=mod;
if((*y1=*x1-t1)>M0) *y1+=mod;
if((*x1+=t1)>M0) *x1-=mod;
}
for(uni i=0;i<=lim;++i)
a[i]=(ll)a[i]*b[i]%mod;
for(uni i=0;i<lim;++i)
if(i<r[i]) swap(a[i],a[r[i]]);
for(uni mid=1,cnt=0;mid<lim;mid<<=1,++cnt)
for(uni i=mid<<1,j=0;j<lim;j+=i)
for(uni *x=a+j,*y=x+mid,k=0,*g=pre.gi+(1<<cnt);k<mid;++k,++g,++x,++y){
uni t=(ll)*g**y%mod;
if((*y=*x-t)>M0) *y+=mod;
if((*x+=t)>M0) *x-=mod;
}
for(uni i=0,inv=power(lim,mod-2);i<=n+m;++i)
printf("%u ",(ll)a[i]*inv%mod);
return(0);
}
|
实测跑的很快。
一些悬而未解的问题
上面代码中有这样一句话:
1
| if((*y=*x-t)>M0) *y+=mod;
|
M0 被设为 0x7fffffff 也就是
MaxInt,因为使用 unsigned 加速乘法所以这么写。因为当
unsigned
被设为负数时会向上溢出,这时我们再加一个模数即可溢出回来。
但是还有这样一句话:
显然这样就意味着在 int
范围内自然溢出了,然后我们再把这个自然溢出的数减回来。
这样看来似乎只要这个 M0
能保证大于模数并保证加上一个模数在 unsigned
范围内就能为一个合法的 M0,测试似乎确实如此。
按照这个思路我们可以把 M0 设为 即可减少模数。
但实际上在不同数据下,取模的次数并不为 M0 而减少。
测试得 M0 似乎仍应为 。
我对此暂时没有更多想法。
FFT 的真正的优化
上面所提到的优化已经可以切题了,但我们仍有方法做优化。
毕竟谁会出裸的 FFT 啊,肯定要配合一些奇怪的东西跑的嘛
以下内容可于 2016
年国家集训队论文中的《再探快速傅里叶变换》中找到。
所以看不懂请去找原作者
设现在要求
(多项式的次数 已调整为 2
的幂)。
设
设 为 的点值表示法的第 项,即为 .
设
即共轭复数(IDFT 时出现过)。
那么
于是我们仅用一次 DFT 就可以算出 和 .
算完考虑怎么得到 和
,于是有:
于是我们把两次 DFT 变成了一次。
因为PDF不能复制,上面这一大大大大段都是手打的,渲染得我 Typora
都卡了
又不是我写论文搞这么多干什么
而且这玩意背板子就好了,理解毛线
这个优化还有很多其他写法,不过在数学部分上是大部分相同的。
在原论文中还有进一步优化为三次单倍长度 DFT 的方式,即“1.5 次
DFT”,但是我太蒻了并不会。
CODE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| #include<cmath>
#include<cstdio>
#include<iostream>
#define N 262145
#define uni unsigned
#define reg register
#define lf long double
#define cp(a,b) (complex{a,b})
using namespace std;
const lf PI=acos(-1);
uni n,m,lim=1,l=-1,r[N];
char BuF[1<<26],*InF=BuF;
struct complex{
lf r,i;
complex operator+(complex b){return(cp(r+b.r,i+b.i));}
complex operator-(complex b){return(cp(r-b.r,i-b.i));}
complex operator*(complex b){return(cp(r*b.r-i*b.i,r*b.i+i*b.r));}
complex operator/(uni b){return(cp(r/b,i/b));}
complex operator~(){return(cp(r,-i));}
}a[N],ans[N],wn[N];
template<typename T>void read(T &x){
for(;48>*InF||*InF>57;++InF);
for(x=0;47<*InF&&*InF<58;x=x*10+(*InF++^48));
}
void dft(complex *a){
for(reg uni i=0;i<lim;++i)
if(i<r[i]) swap(a[i],a[r[i]]);
for(reg uni mid=1,cnt=l;mid<lim;mid<<=1,--cnt)
for(reg uni i=mid<<1,j=0;j<lim;j+=i)
for(reg uni k=0;k<mid;++k){
complex x=a[j+k],y=wn[k<<cnt]*a[j+mid+k];
a[j+k]=x+y;
a[j+mid+k]=x-y;
}
}
int main(){
fread(BuF,1,1<<26,stdin);
read(n);read(m);
for(reg uni i=0;i<=n;read(a[i++].r));
for(reg uni i=0;i<=m;read(a[i++].i));
for(;lim<=n+m;++l) lim<<=1;
for(reg uni i=1;i<lim;++i)
r[i]=(r[i>>1]>>1)|((i&1)<<l);
for(reg uni i=0,r=lim>>1;i<r;++i)
wn[i]=cp(cos(i*PI/r),sin(i*PI/r));
dft(a);
a[lim]=a[0];
for(reg uni i=0;i<lim;++i){
ans[i]=cp(0,-1)*(a[i]+~a[lim-i])*(a[i]-~a[lim-i])/4;
wn[i]=~wn[i];
}
dft(ans);
for(reg uni i=0;i<=n+m;++i)
printf("%u ",(uni)(ans[i].r/lim+0.5));
return(0);
}
|
这份代码实测跑的比 NTT 慢一点,但仍有意义(就在下面)。
MTT
一般认为是任意模数数论变换。
不过已经广泛到还指拆系数 FFT 了。
似乎实际上是“毛爷爷的 NTT”的意思?
谷歌告诉我们展开是 Arbitrary Modulus Number Theory
Transformation 即 AMNTT
总之(至少名字)应该是个民间发明,因为维基上真的没有
NTT 的局限在于模数有限制(某著名的 998244353 从 UOJ
跑出来之后烂大街了,然后你发现就没有人用其他模数), FFT
的局限在于精度低,乘出来的数字一大就炸。
于是就会有出题人放一些奇怪的模数恶心人,比如(杭电 ACM
中出现过的)998244352 或 998344353 什么的。
有两种思路:
三模数 NTT
思想比较简单,就是用 NTT
能用的若干模数做三次,然后利用中国剩余定理两两合并。
一般取三个,因为两个精度不够。(所以 99.9999% 的地方都叫三模数 NTT
包括这里,虽然不一定是三个)
也就是先求出结果在足够精度下的真值,然后取模。
优化
如果题目给的模数足够小只用两个就够了
无
所以学什么嘛,这么慢。
以掩饰我懒所以不会
拆系数 FFT
考虑把 FFT 运算中的数变小以提高精度。
考虑
,则我们可以把一个数 表示为 .
然后考虑把原多项式用这种方法拆成两个多项式,一共四个多项式,然后乘出四个多项式,然后再合并起来。
没了。
实际情况就是根本不懂技术细节只会瞎胡。
优化
首先这玩意 8 次 DFT 已经吊打 NTT 9 次了好吧
非常简单,用上面提到的方法将 4 次 DFT , 4 次 IDFT 两两合并,就只剩 4
次 DFT 了。
如果使用“1.5 次 DFT”可以做到“3.5 次
DFT”,当然柿子过于复杂所以效果不明显。
同时,一个重要的点就是对于每一个单位根,我们直接计算而不是取一次单位根的幂,这样可以保证精度。
实测取一次单位根的幂会在 luogu 上 WA 两个点。
CODE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| #include<cmath>
#include<cstdio>
#include<iostream>
#define N 262145
#define uni unsigned
#define reg register
#define lf long double
#define ll uni long long
#define cp(a,b) (complex{a,b})
using namespace std;
const lf PI=acos((lf)-1);
uni n,m,mod,cmod,lim=1,l=-1,r[N];
char BuF[1<<24],*InF=BuF;
struct complex{
lf r,i;
complex operator+(complex b){return(cp(r+b.r,i+b.i));}
complex operator-(complex b){return(cp(r-b.r,i-b.i));}
complex operator*(complex b){return(cp(r*b.r-i*b.i,r*b.i+i*b.r));}
complex operator/(uni b){return(cp(r/b,i/b));}
complex operator~(){return(cp(r,-i));}
}a[N],b[N],p[N],q[N],wn[N];
template<typename T>void read(T &x){
for(;47>*InF||*InF>58;++InF);
for(x=0;47<*InF&&*InF<58;x=x*10+(*InF++^48));
}
void dft(complex *a){
for(reg uni i=0;i<lim;++i)
if(i<r[i]) swap(a[i],a[r[i]]);
for(reg uni mid=1,cnt=l;mid<lim;mid<<=1,--cnt)
for(reg uni i=mid<<1,j=0;j<lim;j+=i)
for(reg uni k=0;k<mid;++k){
complex x=a[j+k],y=wn[k<<cnt]*a[j+mid+k];
a[j+k]=x+y;
a[j+mid+k]=x-y;
}
}
int main(){
fread(BuF,1,1<<24,stdin);
read(n);read(m);read(mod);
cmod=(uni)ceil(sqrt(mod));
for(reg uni i=0,x;i<=n;++i){
read(x);x%=mod;
a[i]=(complex){(lf)(x/cmod),(lf)(x%cmod)};
}
for(reg uni i=0,x;i<=m;++i){
read(x);x%=mod;
b[i]=cp((lf)(x/cmod),(lf)(x%cmod));
}
for(;lim<=n+m;++l) lim<<=1;
for(reg uni i=1;i<lim;++i)
r[i]=(r[i>>1]>>1)|((i&1)<<l);
for(reg uni i=0,r=lim>>1;i<r;++i)
wn[i]=cp(cos(i*PI/r),sin(i*PI/r));
dft(a);dft(b);
a[lim]=a[0];
for(reg uni i=0;i<lim;++i){
p[i]=a[i]*b[i];q[i]=b[i]*~a[lim-i];
}
for(reg uni i=0;i<lim;++i)
wn[i]=~wn[i];
dft(p);dft(q);
for(reg uni i=0;i<=n+m;++i){
p[i].r/=lim;q[i].r/=lim;p[i].i/=lim;
reg ll ac=(p[i].r+q[i].r)/2+0.5,bd=q[i].r-ac+0.5,abcd=p[i].i+0.5;
printf("%llu ",((ac%mod*cmod%mod*cmod%mod)%mod+(abcd%mod*cmod%mod)%mod+bd%mod)%mod);
}
return(0);
}
|
总结
好的,你现在已经切完了 luogu 、 uoj 、 loj 上的模板题了。
现在快去切以下题目吧:
- 「ZJOI2014」力
- Fuzzy
Search
- Kyoya and
Train
- Transforming
Sequence
我太蒻了全都不会
其实大部分时候 FFT/NTT/MTT
都跟网络流算法类似,只要搞出一个卷积的模型跑板子就行了。
所以你为什么会网络流1年多了才会卷积?